
Software engineer's AI stack in 2026
Stop vibe coding and start engineering. Learn the essential AI glossary to build reliable systems with MCP, agents, and rigorous context management.

While 2024 was defined by developers intuitively prompting their way through basic tasks, 2026 is the year of rigorous AI engineering. As we move from simple chatbots to complex agentic systems, the distance between magic and mechanics is narrowing.
Software engineering has always been about managing abstractions and protocols. The transition to AI-integrated development is no different. To build reliable systems, we must move past the hype and master the technical foundation behind these models.
This post provides the essential terms for the modern AI engineering stack.
A shared language is the only way to move from brittle experimental projects to production-ready systems. Vibes are great, but it’s time to start engineering.
Get the free AI Agent Building Blocks ebook when you subscribe:

In this post, you’ll learn
The technical foundations of modern foundation models and their learning processes.
How to manage context and tokens to avoid reasoning degradation.
The protocols and architectures that allow AI agents to interact with external tools.
Modern development paradigms and verification strategies for agentic workflows.
Foundations
Foundation Models & LLMs
Foundation Models are the base layer of our new stack. These models are trained on massive, diverse datasets, allowing them to adapt to a wide range of tasks without needing to be built from scratch. Large Language Models (LLMs) are a specific type of foundation model that has been optimized for processing and generating human language, although modern versions are increasingly multi-modal, handling text, images, and audio seamlessly.
The Transformer Architecture & Attention
The Transformer Architecture is the core algorithmic discovery that made modern AI possible. By using a mechanism called Attention, these models can process all parts of an input sequence at once instead of reading word by word. This parallel processing allows the model to understand complex relationships and nuances in code or text that earlier techniques would miss entirely.
Training, Fine-tuning, and RLHF
Training is the process of building the model’s base intelligence. Pre-training establishes general knowledge across the internet and books. Fine-tuning is a post-training technique where you perform additional training on specific data, like your company’s codebase, to specialize the model. RLHF (Reinforcement Learning from Human Feedback) is then used to align the model’s responses with human intent and safety standards, ensuring the output is actually helpful for a developer.
Inference & Tokens
Inference is the act of running the model to generate a response. The cost and performance of inference are determined by Tokens, the basic units of data the model processes. Modern engineers must track Token Windows (the model’s memory limit, aka Context Window or Context Memory) and use Cache Tokens to minimize latency and cost by reusing frequently used prompt prefixes. Performance is boosted when inference is optimized, like OpenAI’s Codex 5.3 spark running on 1k tokens/second.
The Interface
Prompt Engineering & Prompt Libraries
Prompt Engineering is the systematic practice of crafting inputs to get the best possible response from a model. It involves more than just writing instructions; it includes managing Prompt Libraries, which are versioned, tested collections of prompts used across a team or application to ensure consistent and high-quality outputs.
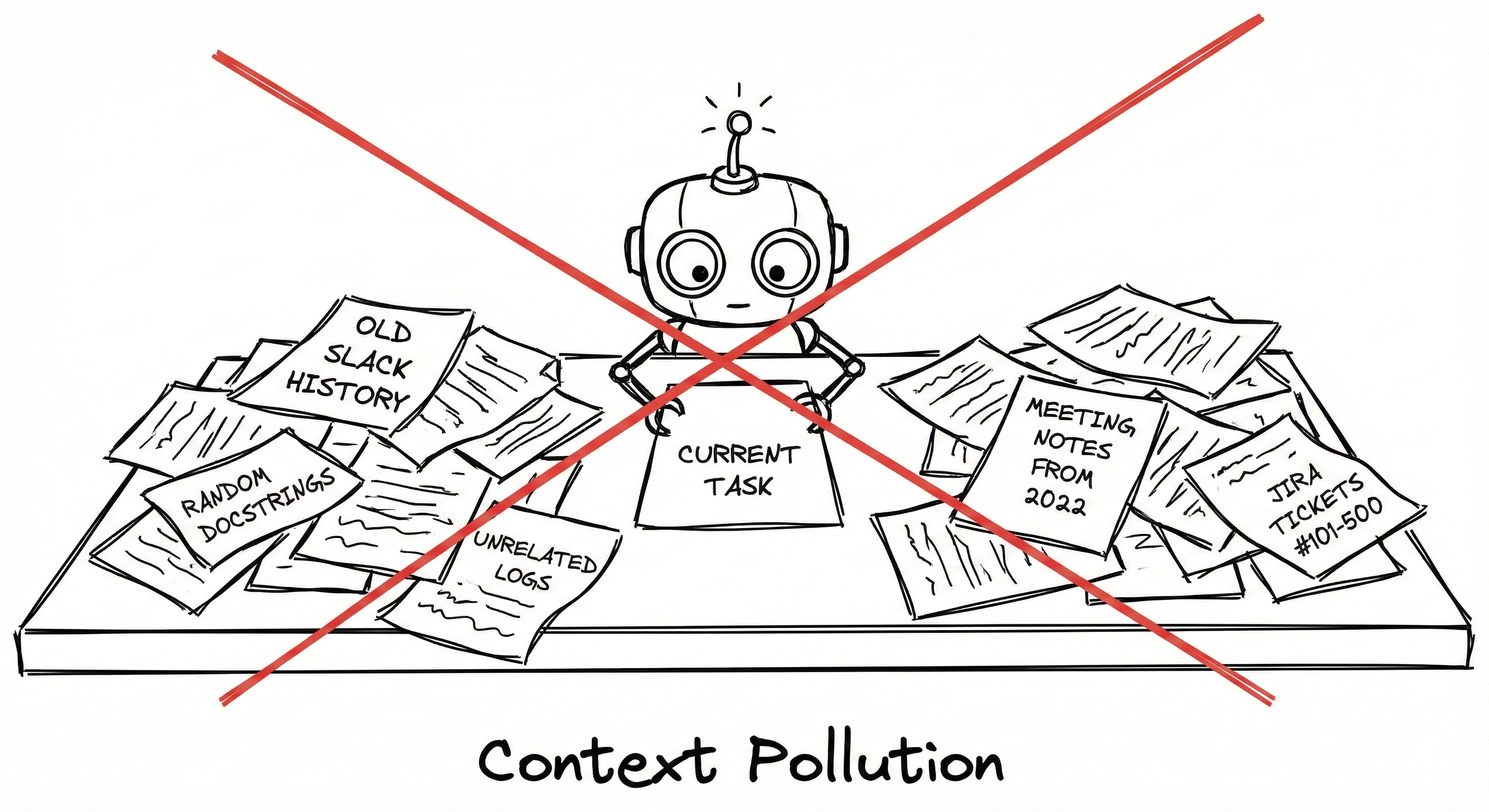
Static Context & Dynamic Context
Context management is the most important factor in model performance. Static Context refers to stable, long-lived information like your entire codebase or architectural standards. Dynamic Context is the temporary, task-specific information for the current interaction, such as current problem descriptions, intermediate code versions, and debugging information.
Multi-Turn Conversations
Multi-Turn Conversations involve multiple round trips between the human and the machine. This back-and-forth interaction is what enables agentic behavior, allowing the AI to maintain state, plan, and adapt dynamically to new information over the course of a session.
Hallucinations & Grounding
A Hallucination occurs when an AI model generates factually incorrect or fabricated information. To prevent this, engineers use Grounding, the process of providing the model with verifiable facts and context (via RAG or MCP) to ensure its responses are based on reality rather than its training weights alone.