
What Is an AI Native Software Engineer?
Buying Cursor does not make you AI-native. The real skill is defining the context, tools, loops, and evidence that make agents reliable.

Most engineers using AI today are still operating at the manual prompt level.
They ask for code, wait for a diff, review what changed, and repeat. That can work for isolated tasks, but it breaks down when the work needs repo context, team conventions, test evidence, rollout thinking, and clear boundaries around what the agent can touch.
The fact that your company pays for Cursor, Claude Code, Copilot, or Codex does not make you an AI-native software engineer. It means you have access to a tool.
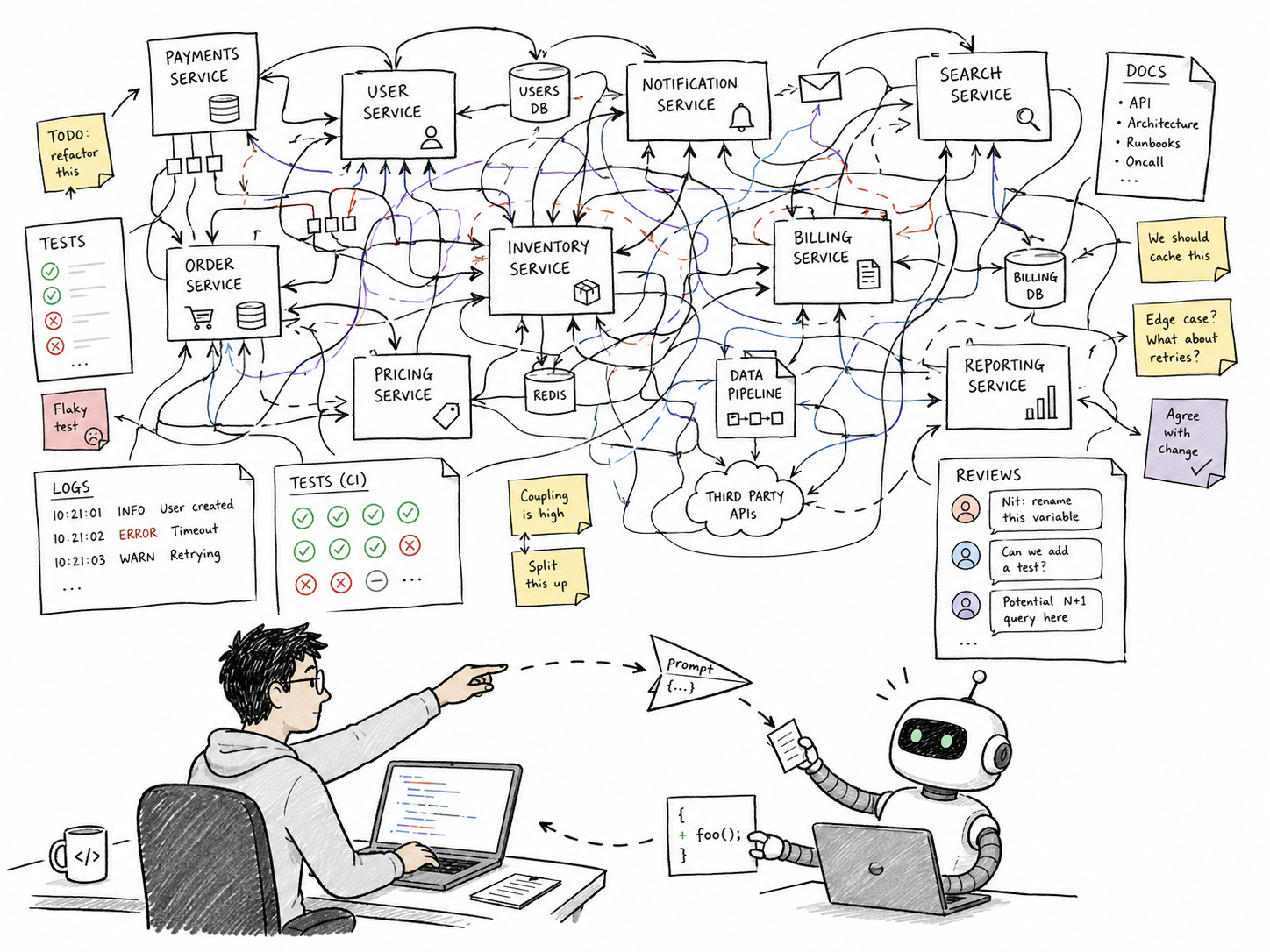
This is where the term “AI native software engineer” should mean something practical.
An AI-native software engineer defines the working system that makes an agent useful on a real codebase: context, memory, tools, permissions, loops, verification, and evidence.
The interesting skill is creating a system where AI can produce reviewable work.
Generating code that compiles is cheap. Increasing the delivery speed of production-ready software is harder, but as you’ll read today, it’s not impossible.
What is an AI-native software engineer?
An AI-native software engineer uses AI as part of the engineering system. The AI harness that you use becomes a workflow component inside the software delivery process.
The difference is whether you can make AI work reliably inside a real repo, with your team's conventions (not the biases of the model), deliver under pressure, adapt fast to changes, and hold a high bar in code reviews.
Here is my definition:
An AI-native software engineer defines the system an AI agent needs to produce reviewable work.
That definition matters because most AI failures I see at work come from missing local knowledge.
The model can write working code, but at Amazon we have A LOT of internal tooling that the models don’t know about. So somehow I have to make the model know how to operate in that ecosystem. And you should do the same.
OpenAI makes this point in its Codex agent loop write-up, where the harness orchestrates the user, model, tools, and context needed to do meaningful software work.
The model is one pluggable part of the system.
The useful distinction looks like this:
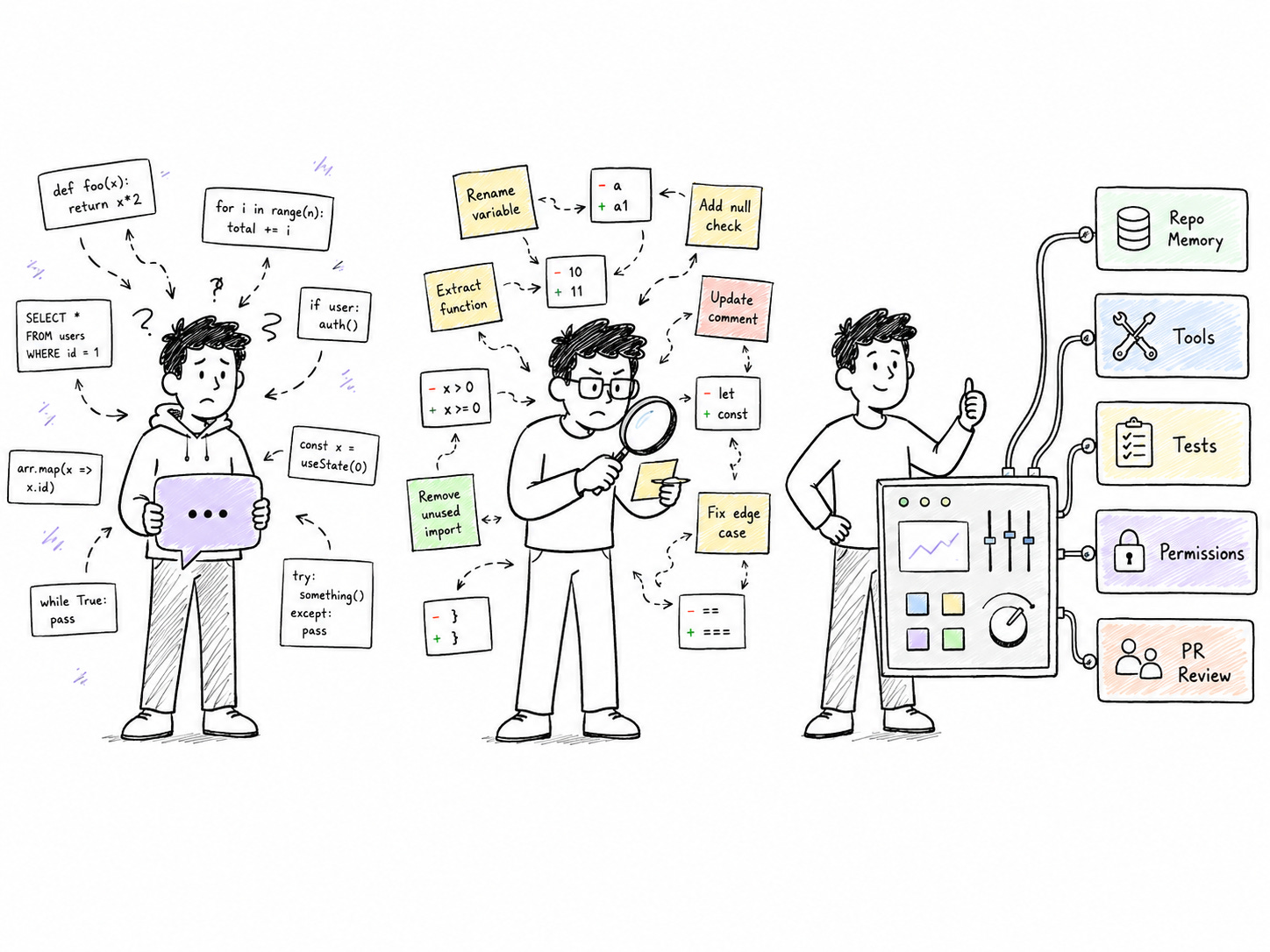
AI tool user: Their company gives them a license and asks the model to implement a task, usually gets code that works for the most part but doesn’t manage well the edge cases and changes in direction. AI speeds things up but lowers quality
AI-assisted engineer: Gives good context, reviews the diff, iterates with AI, changing some pieces of code until the code meets their standard. Often feels like they have to micromanage AI and wonders if they would have been faster by themselves.
AI-native engineer: Defines a system for AI to work: specs, repo memory, tools, execution loops, produces reviewable work to keep the human in the loop at the right time, verification papertrail. This engineer takes time to create the system and always keeps refining it. But it’s like a plane: once it takes off, it’s faster than any other approach.
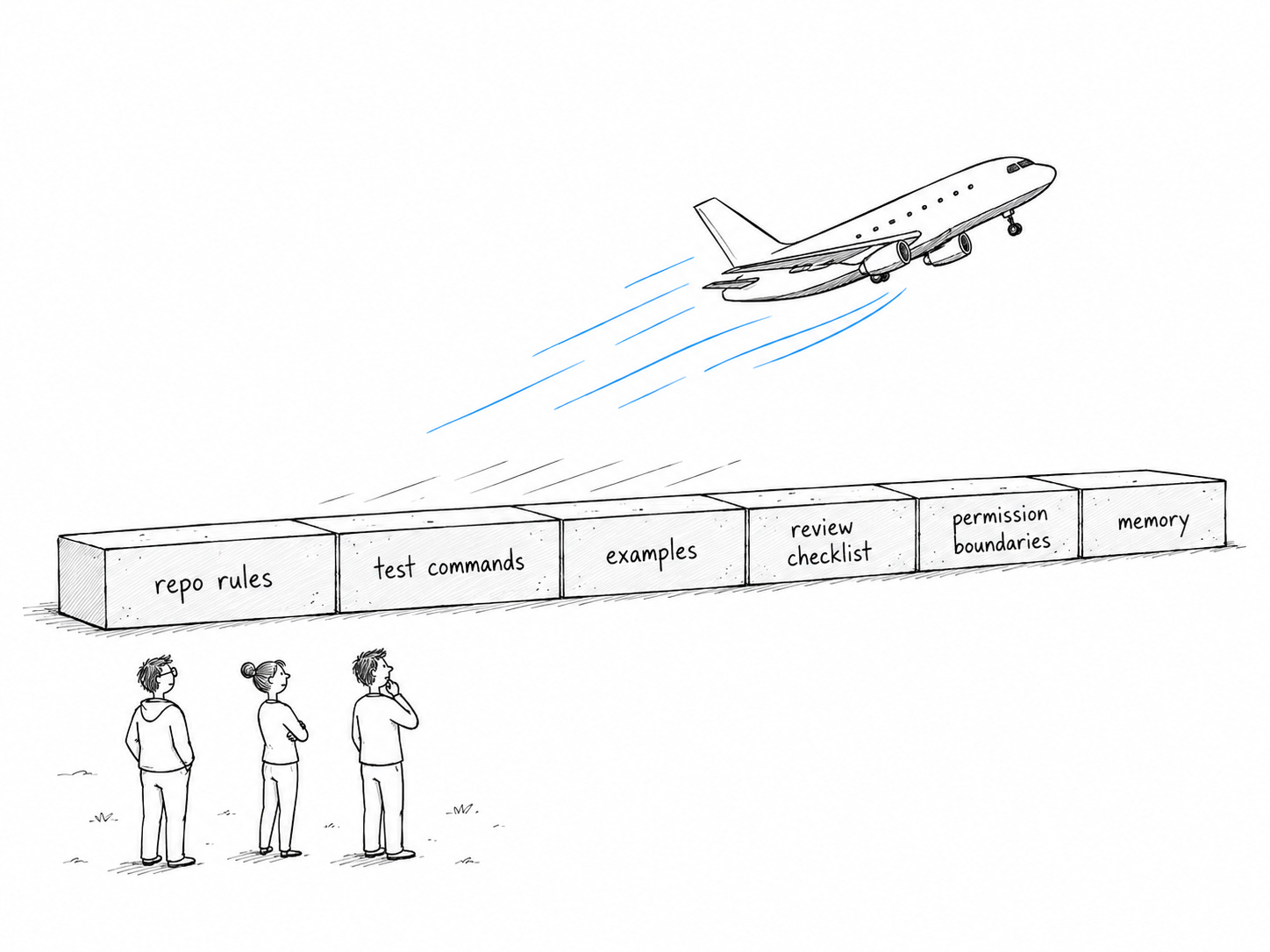
The third model doesn’t care too much about benchmarks or the new model because they have a system where it’ll just change one string and keep working with the new model.
It sounds boring because it is.
Most things that work are boring.
From better prompts to better operating systems
Prompting still matters. A vague instruction creates vague work.
But nowadays it’s no longer the highest-leverage layer for serious software work. The better question is: what operating environment does the agent need so the prompt stops carrying the whole system on its back?
Anthropic’s context engineering guidance pushes in this direction. Agents should assemble understanding layer by layer, keep only what matters in working memory, and use tools to retrieve what they need instead of drowning in every possible document.
OpenAI’s harness engineering article says something similar from the Codex side. A giant AGENTS.md eventually becomes a junk drawer. The better pattern is a short map that points to deeper docs, examples, specs, and checks.
That matches what I see in practice.
The same model can feel brilliant in one workflow and reckless in another.
A useful next step is this breakdown of harness engineering and why production AI agents need tools, state, guardrails, and feedback loops: https://strategizeyourcareer.com/p/harness-engineering-ai-agents
The toolkit is context, memory, tools, loops, and evidence
If I had to reduce AI-native engineering to one checklist, it would be this: