
Scaling Software Engineering with AI
The press says Amazon is adding more human reviews for IA-generated code. AI creates review bottlenecks. Scale your engineering by automating CI/CD pipelines

Get the free AI Agent Building Blocks ebook when you subscribe.

Note: My opinions are my own. I do not speak for a company, and I don’t care what’s true and what’s not from the press releases below.
Recent tech headlines about Amazon and outage incidents miss the point entirely.
The media loves a flashy story about AI breaking code, like this recent article:
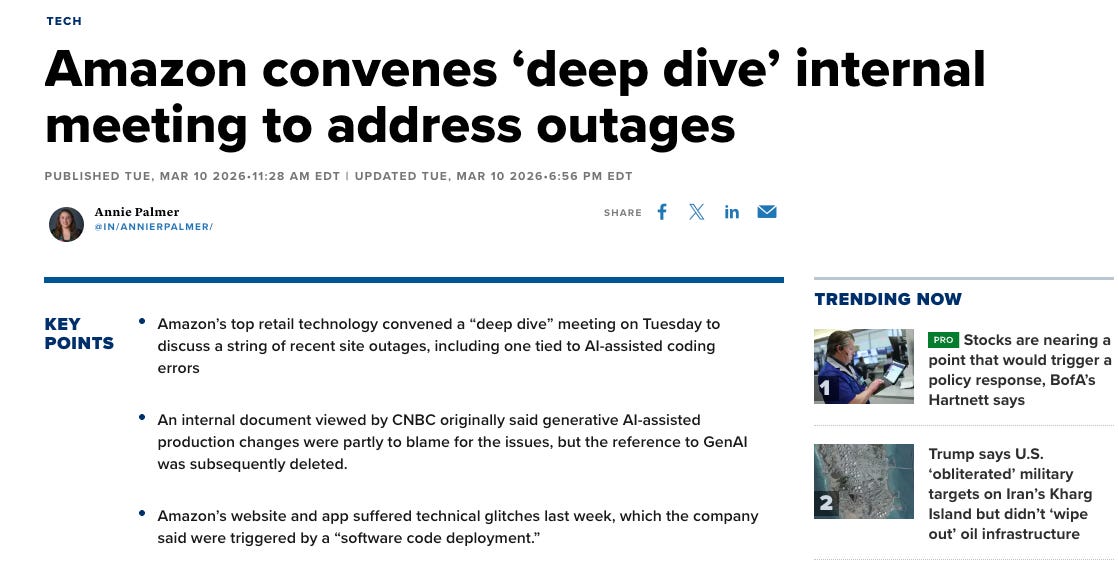
Those apparent leaks got so much attention that even Amazon had to write its own PR communication to correct the narrative.

You should treat any news about big companies with skepticism unless it is communicated directly by someone from the company. Even internally, there are so many layers that direct information is hard to find.
I’m not here to talk about gossip.
I’m here to approach the real problem: How can we do good software engineering with AI?
The core points from the media that I read were:
AI causes outages by breaking production directly or by flooding engineers with so much code that reviews become sloppy.
All non-seniors’ code needs senior approval. Press and social media are making a point that Amazon fired many engineers and is now asking to have engineers as the guardrail.
I think those headlines are looking at this situation the wrong way.
The thesis of modern development is that the bottleneck is no longer coding speed.
Let’s rephrase the problem in this way:
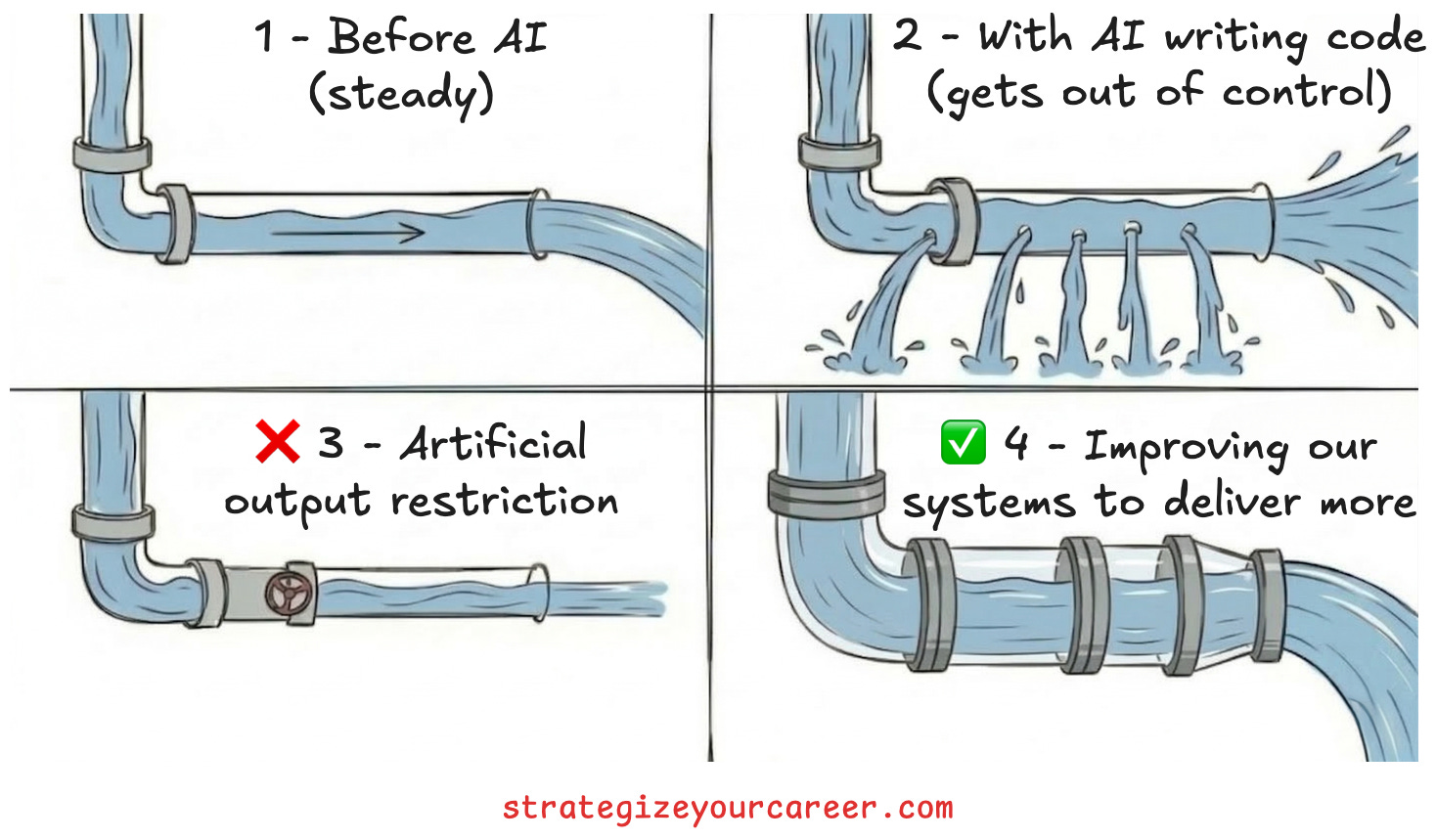
Pre-AI: A company was able to handle 1 diff per engineer per day.
Post-AI: Now, engineers can raise 5 diffs per engineer per day.
So is the press and social media saying that the solution is to hit the brakes and make engineers write only 1 diff per day?
That’s not a good solution.
Companies change their engineering processes when they go from 10 engineers to 1000 engineers. So companies should adapt to AI the same way.
We need to apply good engineering practices to how we use these new tools to become truly productive.
Let’s learn how!
In this post, you’ll learn
Why manual safeguards create a false sense of security and drain productivity.
Concrete steps to automate your deployment pipeline and get your time back.
How the bottleneck in software engineering has shifted from writing code to reviewing code.
How to build an engineering culture that scales with rapid code generation.
The cost of manual safeguards
Let me go back 2.5 years.
I switched teams internally from Amazon retail to the Ring team by the end of 2023. I was told when interviewing for Ring that the company was still in progress to “transition” into Amazon’s ecosystem. The first day, when I arrived at my new desk, I saw we had continuous integration pipelines. So this wasn’t an outdated company at all, right?
Well, the promotions to production environments were disabled in all pipelines.
Deployments were entirely manual, relying on human reviews and checklists. We treated our code like mobile app store releases, freezing updates weeks in advance for testing. This process was built on the belief that human eyes were safer than automated machines.
Teams documented more than necessary: Commit hashes, summary of the changes, links to regression tests, and approvals from multiple leaders. They did all of this documentation by hand (it was before the AI boom).
This manual process gave everyone a false sense of security. Humans make mistakes when reading long checklists and manually verifying hashes. These processes drain productivity and prevent engineers from doing their best work.
We think things are safer when we see them, but the only way to grow and scale is to delegate. And there’s nothing better than delegating to machines.

We needed to automate these steps to actually protect our systems and our time.
7 steps to automate your deployment pipeline
Since those early days, my team has done a lot of automation and applied DevOps learnings to our pipelines to adopt real continuous delivery.
The transition from manual checks to automated deployment requires some specific improvements. I agree that it’s risky to just enable a transition between non-prod and prod without any of these automated guardrails.
This upfront investment in an organization brings great returns in the long run. A team of six engineers can now manage eight services because they do not waste time on manual pipeline tasks (this same team only owned three, from which two were in KTLO).
Here are some of the guardrails needed to have a real CI/CD pipeline
Deploy all your infrastructure as code. This is the best way to maintain environment parity and be able to audit it.
Add testing to the pipeline. Improve the pipeline to run integration tests, canary tests, and load tests automatically before promoting any changes.
Establish robust monitoring. You need to track core metrics like availability, latency, and resource utilization for any backend service. For asynchronous workflows, you should monitor the oldest event and track messages in dead letter queues to measure failure rates. You need these metrics in all non-prod environments too, so you catch issues early in the pipeline and stop deploying them.
And you should also ensure that changes don’t break dependencies. Add contract testing to ensure backwards compatibility.Update your deployment strategy.