
How Software Engineers Make Productive Decisions (without slowing the team down)
A risk-aware framework for making faster engineering decisions without being sloppy

Get the free AI Agent Building Blocks ebook when you subscribe:

Most teams don’t get stuck because problems are impossible. They get stuck because every choice is treated like it’s irreversible. In reality, lots of calls are two-way doors: you can walk through, check the room, and walk back out. Save the caution for the true one-way doors: data migrations, security posture, customer-visible changes with real blast radius.
When I’m unsure, I run a fast, risk-aware filter. If the downside is small, the change is reversible, or I can mitigate quickly, I ship with guardrails. That’s how you move fast without being sloppy.
In this post, you'll learn:
How to tell if a decision is reversible or not
The 3 questions I ask before slowing down
How to move fast without being sloppy
Why speed compounds into career growth
Stop treating every choice like a one-way door
Not every door leads to a cliff, some just swing back open. Two-way doors are things like toggling a feature flag, shipping a non-consumed response field, or swapping an internal library behind an abstraction. If it goes sideways, you flip the switch or roll back.
One-way doors are different. Think data migrations, schema changes, or decisions that can silently corrupt data or take a core service down. At my job, when a migration touches your database and could risk data loss, I’d slow down on purpose: rehearsal in non-prod environments, snapshot plans, read-only windows if needed, and crisp rollback playbooks.
The productivity benefit is knowing the difference before you start. Over-investing in reversible decisions burns time and morale. Under-investing in high-stakes calls burns trust and customer goodwill.
A fast, risk-aware framework (ask these 3 questions)
When a decision lands on your lap, take 1-2 minutes and ask:
1) What’s the impact if I’m wrong?
Is the effect invisible, annoying, or catastrophic? User-visible errors, security regressions, and data integrity issues are “slow-down” territory. On the other hand, shipping a field the client doesn’t yet consume is low risk. I’ve green-lit rollouts like this with smoke tests + feature flag, skipping a day or two of heavy testing because there was effectively no customer impact and rollback was trivial.
2) How hard is it to reverse?
Reversal options change everything. If I can roll back in ~10 minutes because I have alarms, canary checks, and a pre-wired rollback, I bias toward speed. When reversal is painful (e.g., a destructive migration), I do design notes, peer review, and a rehearsal.
3) Can we mitigate fast with a small blast radius?
Sometimes you can’t prevent every issue, but you can limit the blast radius. Canaries, partial rollouts, and scoped feature flags mean we learn quickly without harming many users. A line I actually use with stakeholders:
“Do we need to focus on prevention here, or can we move forward and mitigate fast with a small blast radius if something is wrong? If mitigation is fast and contained, let’s go.”
A tiny decision matrix you can use
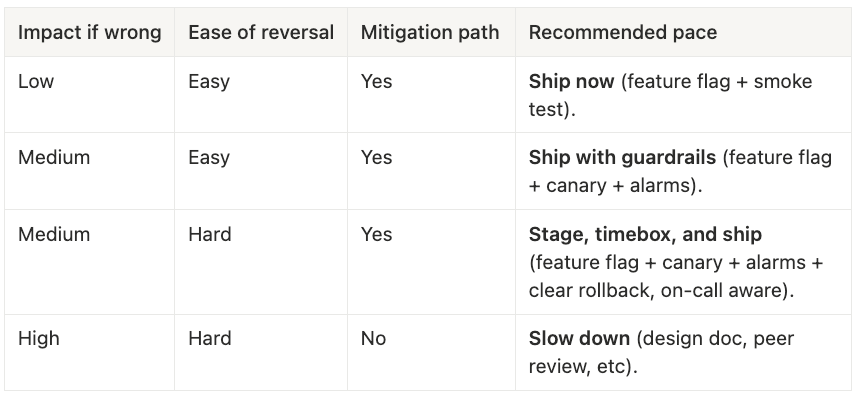
If your situation is somewhere in the middle, pick the stricter option to err on the safe side.
Turn one-way doors into two-way doors (tactics that actually work)
Feature flags and small PRs
Flags are the safest way to keep a single-branch mainline in production. Merge early, merge often, even incomplete work, because the flag hides it. That enables smaller PRs, faster reviews, and quicker rollback. In my experience, for many features, the client hasn’t started working on the changes on their end, which makes these deployments extremely low risk because they aren’t consuming your new changes yet.
Checklist for feature flags:
Default-off flag per risk domain (UI, backend path, integration).
One-line rationale in the PR (“why now, why safe”).
Smoke tests for both on/off states.
Exit plan: when and how to delete the flag.
Canary checks, alarms, and 10-minute rollbacks
Even without a feature flag, speed is safe if your observability and rollback are tight:
Before: canary tests succeeding, metrics emitted.
After: alarms on errors, latency, saturation, and key business metrics.
Abort: scripted rollback (or deploy previous artifact) within ~10 minutes.
I’ve shipped features knowing that if anything trips alarms, the change is reverted quickly. That confidence changes the cost/benefit calculus.
When to timebox vs. slow down
Timebox reversible decisions to 30-60 minutes of research. Make a call, document trade-offs, and move.
Slow down for one-way doors: destructive DB changes, non-backward compatible API changes, payment logic. Do some shadow testing to properly mimic production.
Two-minute safety-net before shipping:
Write a one-line rationale.
Identify the kill switch (flag or rollback).
Ping the right stakeholder if risk > medium.
Confirm alarms cover the critical path.
Common Questions:
How do I know if a decision is reversible?
If you can turn it off, roll it back quickly, or hide it (flag) without customer harm, it’s reversible. If it threatens data integrity, security, or customer trust and can’t be undone cleanly, treat it as a one-way door.
When should I write a full RFC vs. a micro-ADR?
Use a micro-ADR for low/medium-risk calls to keep momentum. Use an RFC or longer design doc for high-risk, hard-to-reverse changes (migrations, auth, billing).
What’s a good rollback target?
Aim for ~10 minutes from alarm to safe state for medium-risk changes. For high-risk changes, rehearse rollback in staging and ensure snapshot/restore times are known.
How do I communicate speed safely?
Frame decisions in risk terms: “Impact small, reversible in 10 minutes, mitigation plan ready.” If mitigation is fast and the blast radius is tiny, bias toward speed.
Do feature flags add tech debt?
Only if you don’t clean them up. Track flags, add an “expiry” note in your micro-ADR, and remove them once the decision is proven.